Member-only story
K-Means Clustering in Python: A Beginner’s Guide
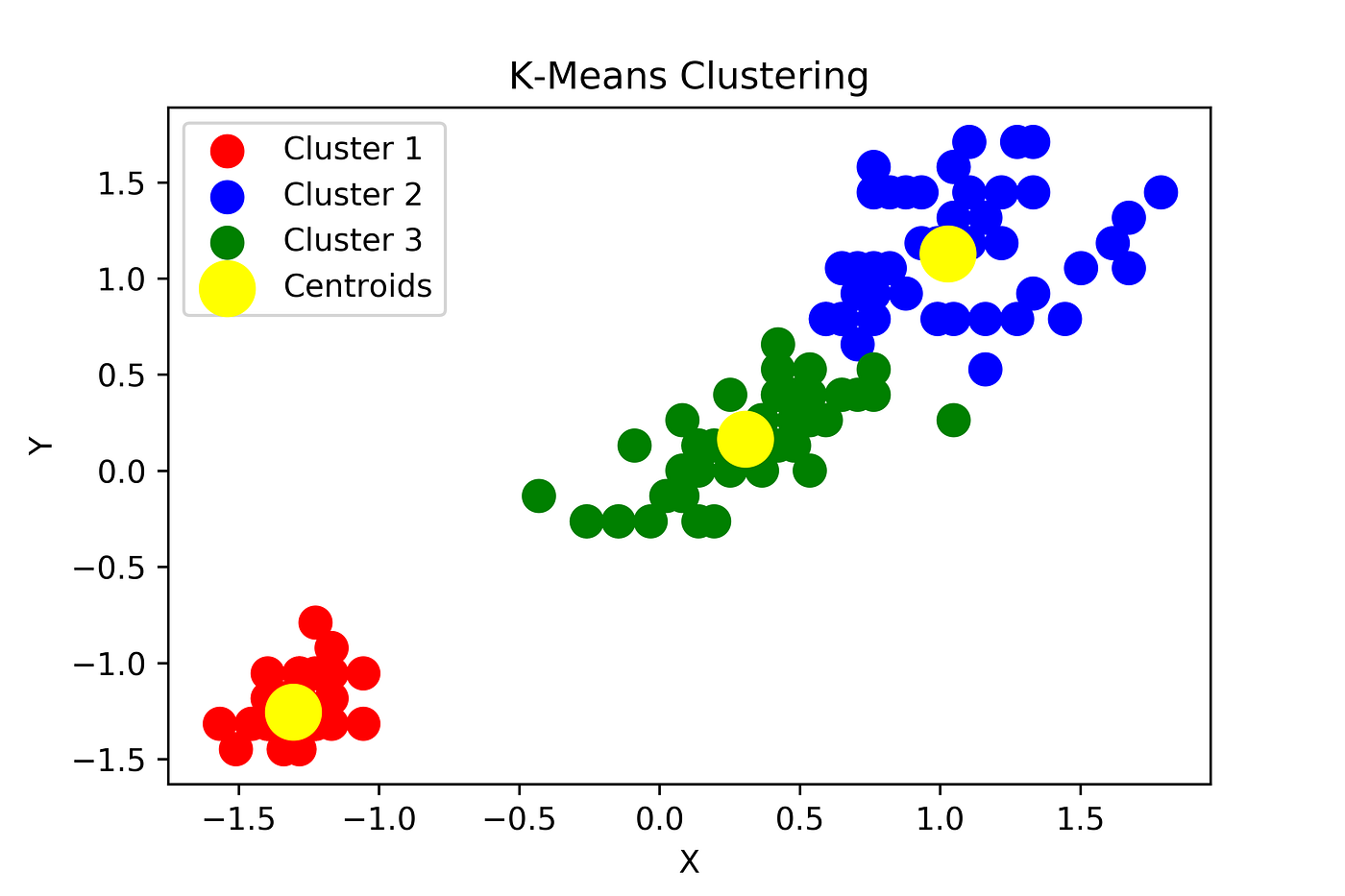
K-means clustering is a popular unsupervised machine learning algorithm used to classify data into groups or clusters based on their similarities or dissimilarities. The algorithm works by partitioning the data points into k clusters, with each data point belonging to the cluster that has the closest mean.
In this tutorial, we will implement the k-means clustering algorithm using Python and the scikit-learn library.
Step 1: Import the necessary libraries
We will start by importing the necessary libraries for implementing the k-means algorithm. We will use NumPy for numerical computing, pandas for data manipulation, matplotlib for data visualization, and scikit-learn for the k-means algorithm implementation.
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as pltThe above code imports the necessary libraries for implementing k-means clustering in Python.
numpy(imported asnp) is a numerical computing library in Python, used for working with arrays and matrices.pandas(imported aspd) is a data manipulation library used for handling and analyzing tabular data.KMeansis a class fromsklearn.clusterthat represents the k-means clustering algorithm.matplotlib.pyplot(imported asplt) is a data visualization library in Python.
Step 2: Load the dataset
For this tutorial, we will be using the iris dataset, which contains information about the lengths and widths of the petals and sepals of different iris flowers. We will load the dataset using the load_iris() function from scikit-learn.
from sklearn.datasets import load_iris
iris = load_iris()The above code imports the load_iris function from the sklearn.datasets module and uses it to load the famous Iris dataset. The Iris dataset contains…
