Member-only story
Gaussian Mixture Models (GMM) Clustering in Python
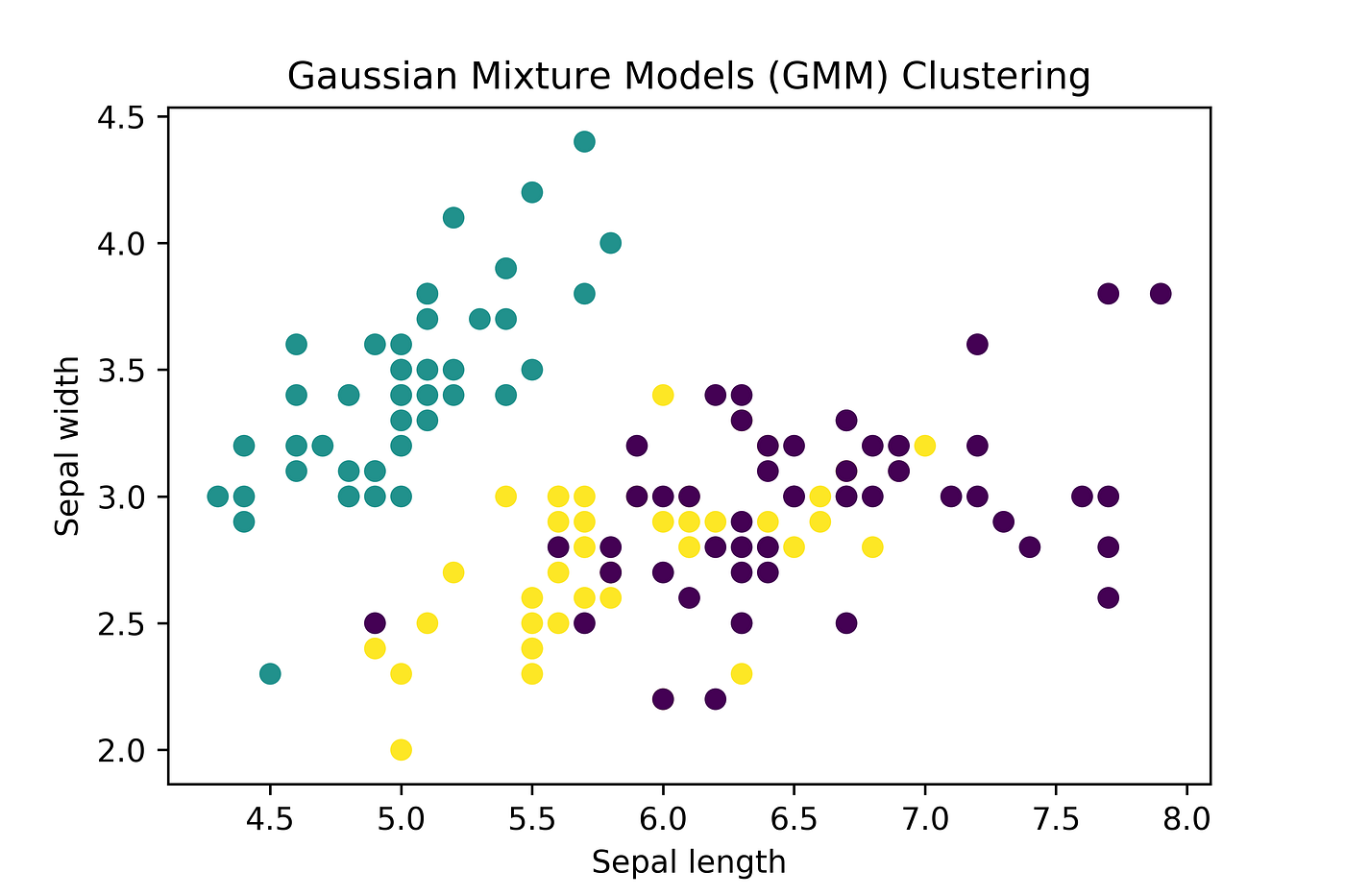
Gaussian Mixture Model (GMM) is a probabilistic model used for clustering, density estimation, and dimensionality reduction. It is a powerful algorithm for discovering underlying patterns in a dataset. In this tutorial, we will learn how to implement GMM clustering in Python using the scikit-learn library.
Step 1: Import Libraries
First, we need to import the required libraries. We will be using the numpy, matplotlib, and scikit-learn libraries.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixtureThe above code imports the necessary libraries to implement Gaussian Mixture Models (GMM) clustering in Python.
numpy is a popular library for numerical computing in Python. We import it and give it the alias np for brevity.
matplotlib.pyplot is a module within the Matplotlib library that provides a convenient interface for creating plots and charts. We import it and give it the alias plt for brevity.
sklearn.mixture is a module within the Scikit-learn library that provides a class for implementing GMM clustering. We import the GaussianMixture class from this module.
By importing these libraries, we have access to the necessary tools to create a GMM clustering model, fit it to data, and visualize the results.
Step 2: Load Data
In this tutorial, we will be using the iris dataset. The iris dataset is a classic dataset used for classification and clustering. It consists of 150 samples, each containing four features: sepal length, sepal width, petal length, and petal width. The samples are labeled with one of three classes: setosa, versicolor, and virginica.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.targetThe above code loads the iris dataset from the scikit-learn library.
